![[UACA]](../../img/escudo02.gif)
|
|
|
|
|
La Reutilización en computación es un concepto que ha cambiado conforme pasa el tiempo. Al principio consistió simplemente en la facilidad sintáctica que le pemitiera al programador usar subrutinas. Hoy en día reconocemos que una pieza de programación es reutilizable si puede ser usada en la construcción de un nuevo programa o programa producto. Ya no se habla entonces de rutinas y programas reutilizables, sino más bien de reutilizar Artefactos de programación ("software artifacts" en inglés). Recientemente este significado se ha afinado mucho más, pues ahora ya sabemos cuáles son las cualidades que debe tener una buena técnica de reutilización de artefactos de programación [Kru-92]:
Es obvio que el grado de reutilización que se logra al usar la técnica expuesta en este trabajo, es de un nivel relativamente bajo, pues sólo sirve para reutilizar estructuras de datos. Esto no es un pecado, como se explica en [US-94] (pg 1), en donde se define el lugar que ocupan en la taxonomía de reutilización de Biggerstaff [Big-84] las bibliotecas de tipos abstractos de datos.
A la luz de estas definiciones se vislumbran dos maneras
interesantes de evaluar las ideas sobre parametrización ya
expuestas. La primera es mostrar cuán incómoda
resulta la programación al parametrizar usando las
técnicas expuestas en este trabajo, y la segunda es
analizar la pérdida en eficiencia que comporta usar
Binder.pas para implementar contenedores
parametrizables. Después de analizar los resultados
obtenidos bajo esta óptica, al final del capítulo se
dan algunas opiniones moldeadas por los argumentos expuestos.
Como la cantidad de recurso humano que se necesita es el costo de
más alto en que se incurre al crear un sistema,
definitivamente es más importante la facilidad de uso de
una técnica de reutilización que su eficiente
implementación; por eso se hace un análisis de
rendimiento después de discutir el costo cognoscitivo de
uso de Binder.pas. Prueba de esto es la existencia de
lenguajes de programación que usan
recolectores de basura, en los
que muchas veces no es posible determinar apriori el rendimiento
real de un algoritmo (de hecho, Lisp es el lenguaje más
viejo que todavía está en uso, y su gran popularidad
en parte se debe a que utiliza un recolector de basura que ayuda a
que el programador no tenga que invertir esfuerzos en manejar la
memoria dinámica
[PZ-98]).
En toda investigación es su autor quien está
más calificado para criticar los resultados obtenidos, pues
conoce a fondo el trabajo desarrollado. En este capítulo se
mencionan primero todos los defectos y limitaciones de
Binder.pas, y luego
sus virtudes y ventajas. Las críticas que se exponen a
continuación son duras y profundas, quizá un poco
más de lo necesario, pero buscan identificar todas las
limitaciones de la
tecnología expuesta, para
eliminarlas lo más pronto posible. No es rehuyendo la
crítica como se llega a la excelencia.
![[<>]](../../img/index.gif)
![[\/]](../../img/bottom.gif)
![[/\]](../../img/top.gif)
![[<>]](../../img/star.gif)
Conviene mucho, y así lo exige la costumbre de los investigadores, conocer el trabajo realizado en el pasado para usarlo al desarrollar una investigación. Hay bastantes bibliotecas de contenedores parametrizables, pero las más importantes son las siguientes:
CTPinst, aunque con la ventaja de tener el apoyo
del compilador. Sin embargo, esta biblioteca obliga a entregar
los fuentes de los algoritmos, y además duplica el
código para cada
instanciación.
Object.
Libg++ es
una biblioteca basada en la jerarquía de clases del
lenguaje Smalltalk
[GR-83]. Ha sido muy utilizada
porque tiene el apoyo del proyecto
GNU, que busca entregarle a la
humanidad programas reutilizables de alta calidad, a precio
nulo. Libg++ es producto del esfuerzo de Keith
Gorlen
[Gor-87].Libg++, aunque incluye
algoritmos para manipulación de grafos que no se
encuentran en otras bibliotecas.
Los autores de estas bibliotecas han hecho una labor encomiable,
pues en muchos casos han invertido cientos y miles de horas en su
desarrollo. Han condimentado su diseño con el sabor del
lenguaje que en algún momento fue de su preferencia: por
ejemplo, Keith Gorlen usó como modelo la biblioteca de
Smalltalk para implementar Libg++. Lo mismo hizo
Alexander Stepanov, arquitecto de STL, quien antes
trabajó mucho en su biblioteca parametrizable para Ada
[MS-96]. De hecho, Stepanov
logró convencer a
Bjarne Stroustrup (creador del lenguaje C++
[Str-86a]) de que modificara el
lenguaje para adaptarlo mejor a las necesidades de su biblioteca
[Ste-95].
TYPE
TLint = TList < INTEGER >;
VAR
L : TLint; { TList < INTEGER > }
{ ... }
L.Append(1); L.Append(3);
L.Append(2); L.Append(4);
|
Todas estas bibliotecas son similares en su forma de uso. Para
declarar un contenedor, el programador debe
instanciar en una variable
el tipo del contenedor. Por ejemplo, en la
Figura 8.1 aparece la manera de
usar una lista de enteros (se ha usado una sintaxis
"pascalizada" en el ejemplo). En este caso se ha
declarado un nuevo tipo llamado TLint
(T+List+integer)
mediante el artilugio de definir un nuevo tipo: lista de enteros
(este estilo de programación es frecuente en programas
C++). El compilador en este caso debe generar el código
para la lista, especializando los algoritmos al caso del tipo
INTEGER. Este estilo de programación fue
introducido en la famosa biblioteca de componentes Booch
[Boo-87]. Es un estilo directo y
muy intuitivo, pues cuando un programador implementa un contenedor
como TLint, lo usual es que le incluya operaciones
como Append() e Insert(), en lugar de
usar los que se recomiendan en este trabajo:
TList.LinkAfter() (ver
Figura 7.17). En la
Figura 7.3 se muestra el
modelo que corresponde a esta
manera de implementar contenedores y se contrasta con el de la
técnica expuesta en este
trabajo, que se muestra en la
Figura 7.4.
Cabe aquí la pregunta: ¿Por qué hay que
mantener el estilo de codificación de la
Figura 8.1, si se puede lograr
que un contenedor sea parametrizable con sólo implementarlo
manipulando únicamente campos de enlace, como se muestra en
la
Figura 7.4? La respuesta a esta
interrogante es muy simple: ya existe una costumbre muy arraigada
sobre la forma de hacer las cosas, y es muy difícil
cambiarla (es más fácil dejar de fumar, o perder
peso, que abandonar la sintaxis usada en la
Figura 8.1). Por eso todas las
bibliotecas de contenedores que se han diseñado tienen en
común esta manera de usarlas; es más,
difícilmente se les ha ocurrido a esos autores siquiera
imaginar usar una sintaxis diferente. Fue necesario implementar el
instanciador de plantillas CTPinst porque es muy
posible que, si no existiera, muchas personas ni siquiera
considerarían usar Binder.pas.
VAR
L : TList <INTEGER>;
{ ... }
L.Append(1);
L.Append(2);
|
TYPE
Tint = RECORD
i : INTEGER;
link : TLlink;
END;
VAR
L : TList;
n,m : Tint;
{ ... }
n.i := 1; L.Append(n.link);
m.i := 2; L.Append(m.link);
|
En la Figura 8.2 se confrontan
los estilos de parametrización de otras bibliotecas con el
de contenedores parametrizados con Binder.pas. Salta
a la vista que quienes usan Binder.pas tienen que
escribir más código. Como en una lista de tipo
TList puede enlazarse cualquier cosa que contenga un
campo de tipo TLlink, además de escribir mucho
pierden la ventaja de la
verificación fuerte de
tipos que ofrece el compilador (ver
Figura 7.30).
UNIT Utypes;
TYPE
Tint = RECORD
i : INTEGER;
link : TLlink;
END;
|
USES
Envelope, Utypes;
VAR
L : Envelope.TList_Tint_link;
n,m : Tint;
{ ... }
n.i := 1; L.Append(n);
m.i := 2; L.Append(m);
|
CTPinst
Si se usa una plantilla de las que CTPinst puede
instanciar, el estilo de programación que se puede usar es
el que se muestra en la
Figura 8.3. La situación
ahora no es tan preocupante como antes, pues mediante el tipo
TList_Tint_link, definido en la unidad
Envelope.pas, que
genera CTPinst, ya el programador cuenta con
verificación fuerte de tipos. Pero ahora surge otro dilema:
además de definir el tipo Tint que sólo
contiene un número entero, hay que crear otro módulo
aparte, llamado Utypes.pas en este ejemplo, que
contiene la definición del tipo Tint.
Además, el uso de tipos de interfaz como
TList_Tint_link implica que la invocación a
cada operación del contenedor es indirecta, lo que
disminuye la eficiencia.
Aparentemente no vale la pena del todo usar Binder.pas: la
única ventaja es que todas las instancias de la lista usan
el mismo código. Surge entonces la siguiente duda: ¿No
sería mejor modificar CTPinst para que en
lugar de instanciar contenedores más bien instanciara
plantillas como lo hace un compilador de Ada o C++? ¿O tal
vez es mejor invertir esfuerzos para implementar un preprocesador
para incluirle a Pascal la construcción
TYPECAST de la
Figura 7.45?
Estas preguntas no tienen una fácil respuesta, pues parece
que todo el esfuerzo invertido en producir Binder.pas
se pierde cuando el lenguaje incorpora plantillas en su sintaxis.
Pero todavía hay más.
UNIT List;
TYPE
Tnode = OBJECT
link : ^Tnode;
END;
TList = OBJECT
_last : ^Tnode;
PROCEDURE Append(VAR n: TNode);
END; { TList }
|
USES
List;
TYPE
Tint = OBJECT(List.Tnode)
i : INTEGER;
END;
VAR
L : TList;
n,m : Tint;
{ ... }
n.i := 1; L.Append(n);
m.i := 2; L.Append(m);
|
En la Figura 8.4 se muestra
cómo es posible simular en parte lo que se hace con
Binder.pas. La idea es que los elementos que
están almacenados en una lista sean extensiones del nodo de
la lista, por lo que contienen el
campo de enlace de la lista. Como
ocurre con el ejemplo de la
Figura 8.2, en este caso se
pierde la verificación fuerte de tipos del compilador y,
además, un mismo elemento no puede estar enlazado en
más de un contenedor (si el lenguaje soporta la herencia
múltiple entonces el mismo elemento no puede estar enlazado
en dos instancias del mismo tipo del contenedor, aunque sí
puede estar en dos o más contenedores de diferente tipo).
La parametrización por herencia fue propuesta hace bastante
tiempo por los pioneros de la programación por objetos, en
el lenguaje SIMULA
[DMN-70]. Luego esta
técnica de parametrización ha sido usada por
Bertrand Meyer
[Mey-86], padre del lenguaje
Eiffel,
[Mey-88], y por los adeptos al
lenguaje Oberon-2
[Mös-94], para
implementar bibliotecas de contenedores parametrizables como se
muestra en la
Figura 8.4. Incluir de forma
explícita en un registro el campo de enlace es precisamente
la
técnica para parametrizar de
Binder.pas, aunque también se puede lograr ese
efecto usando herencia. Sin embargo, la parametrización de
contenedores por herencia usada en Oberon-2 tiene las
siguientes limitaciones:
Next() y
SetTo() (que tiene la misma función que
Bind()), y agrega
Iterator.ForAll(PROCEDURE) que lo que hace es
aplicar un procedimiento a todos los elementos del
contenedor.TContLnk.Binder.pas, no se hace la
importante separación entre el campo de enlace y el
elemento almacenado en el contenedor, lo que le quita
consistencia teórica.Copy() o Swap() para
un campo de enlace, al mismo tiempo que se prohibe su uso.
No hay más incomodidades producidas por el uso de
Binder.pas, aunque en realidad la mayor parte de los
inconvenientes mencionados son producto de la formación
común a todos los científicos de la
computación, que aprenden que la forma correcta de percibir
una estructura de datos es aquella en la que no están
separados los campos de enlace del contenedor del elemento
contenido. Si esta barrera mental se elimina, entonces el estilo
de codificación que requieren los contenedores
parametrizados con Binder.pas no es muy distinto al
tradicional.
Sólo es el programador del contenedor quien debe seguir
cierto protocolo relativamente estricto para implementar su ADT,
pues el programador cliente del contenedor no necesita conocer
esos detalles: le basta incluir en los objetos que desea almacenar
en el contenedor el campo de ligamen, y de ahí en adelante
el código es similar al que el programador
escribiría si no usa el contenedor parametrizable. La
barrera mental en contra de Binder.pas se parece
mucho a la que al principio existió contra la
programación por objetos. De hecho, una
tabla de métodos virtuales no
es más que un vector de punteros a funciones.
Desde el principio Ada contó con paquetes genéricos,
y a partir del año 1990 lo mismo ocurrió con C++,
por lo que la comunidad académica quedó satisfecha
con las implementaciones de contenedores parametrizables que
recurren a la especialización de plantillas, y dejó
de estudiar los ADT's para dedicarse a solucionar otros problemas.
El problema que representa no compartir el código de los
contenedores, que agranda los programas, simplemente dejó
de existir, pues las máquinas progresivamente han aumentado
exponencialmente su capacidad de proceso y de memoria. La
computadoras personales de los noventas son mucho más
potentes que las computadores que ayudaron a posar al primer
hombre en la Luna a fines de los sesentas. Por eso, aunque ya
todos los ingredientes para hacer la "salsa
Binder.pas" existían hace mucho tiempo, nadie
se había molestado en hacer la receta.
A la luz de los argumentos esgrimidos en estos últimos
párrafos, examine el lector de nuevo el ejemplo de la
Figura 8.2, y el de
Figura 8.3: no hay gran
diferencia en los estilos de codificación, pero los
contenedores que han sido parametrizados con
Binder.pas no tienen el problema de las otras
bibliotecas, en donde cada instanciación genera una
versión diferente del módulo parametrizado, y en las
que no es posible usar una sola versión del código
objeto, que pueda ser distribuida sin entregar los fuentes de los
programas. La especialización de las plantillas contribuye
a que el tamaño de los programas crezca y crezca.
¿Es necesario reducir el tamaño de los programas? Las
empresas productoras de programas han respondido negativamente a
esta pregunta, pues, conforme pasa el tiempo, producen programas
cada vez más grandes. Por ejemplo, la primera
versión del procesador de palabras Word de
MicroSoft era muy
pequeña, hasta el punto de que se distribuía en un
disquete de 800 kilobytes. Las versiones más modernas de
este mismo programa ocupan cientos de megabytes, aunque la
funcionalidad agregada no es cien veces mayor. Aunque los
computadores tenga 32, 64, 128 o un millón de megabytes de
memoria, ciertamente llegará el momento en que sea
necesario reducir de nuevo el tamaño de los programas.
Cuando llegue ese momento, tecnologías similares a
Binder.pas serán parte de la respuesta.
En el Capítulo 7 de [LG-86] se describe extensamente otro método para implementar ADT's en Pascal que requiere, al igual que los tipos opacos de Modula-2, definir un puntero para cada instancia del ADT. Lo malo de esa propuesta es que está orientada a que todos los objetos manipulados por un programa sean accesados por medio de punteros, o sea, que usa semántica de referencia. Este excesivo uso de punteros resulta en programas innecesariamente ineficientes, que deben pagar un sobretrabajo significativo para cada instancia de un objeto, pues se necesita un puntero que lo referencie; esta técnica tampoco protege la parte interna del ADT. Pero el uso de punteros tiene una ventaja: no es necesario distribuir código fuente que implementa el ADT para que el programador cliente use el contenedor polimórfico, aunque sí se pierde la verificación fuerte de tipos del compilador.
Los módulos parametrizados con Binder.pas
tienden a ser estructuras de datos de bajo nivel. En la biblioteca
STL de C++ es posible componer unos módulos con otros. Por
ejemplo, los adaptadores para contenedores existen gracias a la
armónica y astuta conjunción de las plantillas y la
sobrecarga de identificadores. La declaración:
stack< vector< char *> > S;
declara una variable "S" que es una pila
(stack) cuya implementación usa un vector. Con
gran facilidad el programador cliente de la biblioteca STL puede
cambiar su contenedor:
stack< list< char *> > S;
Ahora "S" es de nuevo una pila, pero la
implementación usa una lista en lugar de un vector. Este
tipo de maleabilidad se puede lograr con Binder.pas,
pero no cambiando sólo una línea de código.
Por eso se ha afirmado que STL es el paradigma actual de parametrización. Examinemos el siguiente ejemplo, tomado de [MS-94] (pg 641):
template <class BinaryFun, class T>
class IndirectBinaryFun {
BinaryFun b;
public:
IndirectBinaryFun() {}
operator()(T* x, T* y) { return b(*x, *y); }
};
|
Con código como el de la
Figura 8.5 es posible transformar
un algoritmo genérico para que trabaje con un vector de
punteros en lugar de manipular directamente los valores. Esto
sirve, en particular, para instanciar algoritmos de ordenamiento
como el qsort() para que, al ordenar, intercambie
punteros en lugar de mover por todo lado los valores. Este tipo de
expresividad sólo se logra con la conjunción de
muchas cualidades del lenguaje, ¡y con mucha perspicacia!
Todo programador espera que, si necesita un nuevo contenedor, lo pueda obtener combinando los anteriores. La esperanza es que muy pronto (en un plazo no mayor de cinco años), la humanidad como un todo cuente con todos los contenedores que se necesitan, a un costo bajo y sin sacrificar eficiencia. En ese momento los contenedores parametrizables dejarán de ser un problema, y se convertirán simplemente en uno de los activos que la humanidad tiene, de la misma forma que hoy en día disfrutamos a un costo mínimo de la aspirina, la rueda o la navegación.
En última instancia es necesario producir una biblioteca de componentes de programación que sean independientes de la plataforma donde se utilicen. Para mejorar su eficiencia, incluirá herramientas automáticas para lograr la portabilidad de algunas de sus partes, sin desaprovechar las ventajas propias de cada plataforma. Los requerimientos originales de trabajo que se han seguido al producir las primeras implementaciones parametrizables en Pascal de los tres contenedores más importantes, son éstos:
1) o,
cuando más, O(n).1).La puerta que abre la posibilidad de distribuir el código de un contenedor parametrizable también permite luego lograr que la misma implementación pueda utilizarse desde varios lenguajes, pues las interfaces entre lenguajes ya están muy bien definidas. De esta forma un programador podría implementar una biblioteca de contenedores en su lenguaje preferido, Pascal por ejemplo, la que luego podría ser utilizada por los programadores C++ y Ada. Eventualmente sería posible incluir dentro del sistema operativo, como un servicio adicional, una biblioteca de contenedores que pueda ser compartida por todos los programas, lo que ayudará a mejorar la eficiencia de los sistemas de cómputo. Una forma sencilla de lograr este mismo objetivo es distribuir la biblioteca binaria de contenedores como una Bibliotecas de Enlace Dinámico (DLL: Dynamic Link Library), pues todos los sistemas operativos actuales tienen un buen soporte específico para manejar este tipo de bibliotecas de código objeto. Otra alternativa es usar tecnologías como CORBA [Bet-95].
Si es posible que desde varios lenguajes se pueda accesar la misma implementación de una biblioteca, también es posible que la misma biblioteca se pueda trasladar con relativa facilidad a otras plataformas, simplemente recompilando el código fuente. Por eso es natural incluir soporte para múltiples plataformas en la lista de requerimientos.
Una biblioteca que cumpla con dichos requerimientos aumentará su capacidad de reutilización. Al permitir ocultar el código fuente de una implementación se logra proteger la inversión intelectual del programador especializado, lo que aumentará la rentabilidad económica de construir componentes de programación. La especialización es muy importante pues es el motor que impulsa tanto al progreso como a la productividad económica; este es el incentivo económico que se necesita para producir bibliotecas de componentes de altísima calidad.
Las bibliotecas que están disponibles actualmente no
cumplen con todos estos requisitos. Por ejemplo, como las
bibliotecas STL
[STL-95] y Libg++
[Libg++95] están
implementadas usando casi únicamente archivos de encabezado
o macros del preprocesador de C, no es posible distribuir la
biblioteca sin que el cliente final también obtenga el
código fuente de todos los algoritmos que se usan en la
implementación. Lo mismo ocurre con las bibliotecas para
Ada, pues para usar paquetes genéricos también hay
que entregar los fuentes de los programas. Como el uso de
plantillas y paquetes genéricos requiere que el compilador
recompile una gran parte de la biblioteca cada vez que se
instancia un contenedor, la velocidad de compilación
disminuye, lo que incrementa el costo de producción de una
aplicación (por suerte las máquinas actuales son tan
potentes que este problema se ha minimizado). Otro problema del
uso de plantillas es que para los depuradores simbólicos a
veces es difícil seguir el código fuente cuando se
ejecuta el programa.
|
Binder.pas con otras bibliotecasLa Figura 8.6 es una tabla comparativa en que se muestran las principales implementaciones que existen para varios lenguajes y plataformas junto al grado en que cumplen con estos requerimientos. Por ejemplo, la biblioteca de componentes reutilizables de Eiffel es una implementación nueva de la biblioteca Booch, lo que muestra que no es reutilizable, pues un cambio de lenguaje implica el escribir de nuevo todos los algoritmos. Además, como en la implementación se usa semántica de referencia, tampoco es de gran eficiencia. En esta implementación el código fuente sí está protegido, pues para usar la biblioteca de componentes de Eiffel no es necesario tener acceso a los fuentes. La biblioteca PAL para Ada cumple con casi todos los requerimientos, aunque no protege los fuentes.
En la
Figura 8.6 está la
comparación de Binder.pas con las demás
bibliotecas, en relación con los cinco criterios de
diseño expuestos anteriormente. En la tabla se nota que
sólo los contenedores parametrizados con
Binder.pas
cumplen con todos los requerimientos. Binder.pas es
especial porque es la única biblioteca en la que siempre se
comparte la implementación de los algoritmos, pero sin usar
semántica de referencia
para lograrlo. Se nota también que, si se logra compartir
código, se paga en eficiencia, como es el caso de la
biblioteca de Eiffel, pues como todos sus contenedores lo que
almacenan son punteros a las instancias, incurren en un costo
extra que no hay que pagar si se parametriza con
Binder.pas: en este caso, un contenedor de
"n" elementos agrega una cantidad O(n)
de espacio para el contenedor. Todas las demás, y en
particular STL, son muy eficientes, pero no permiten compartir
código ni tampoco proteger los fuentes de los programas. A
diferencia de los demás, Binder.pas es un
enfoque que se puede implementar en varios lenguajes, no en uno
solo.
Una vez definidos estos requerimientos, cabe discutir los
problemas que comporta el uso de la tecnología que
Binder.pas representa; en los párrafos que siguen se
detalla la lista de objeciones.
Binder.pas se presenta
después.Binder.pas funciona,
a un costo bajo. Después de evaluar los logros
alcanzados, el siguiente paso es obtener un producto de calidad
industrial, implementado para múltiples plataformas,
probablemente en el lenguaje C++, que es el estándar
actual para desarrollo de aplicaciones y sistemas complejos
[Bec-98].Binder.pas se sigue usando el concepto de
"puntero", en tanto que en otras
bibliotecas se puede omitir totalmente este concepto si se esconde
todo detrás del método
Container.Insert(), o si se usan construcciones
sintácticas incorporadas al lenguaje, como los iteradores
de CLU
[LG-86] o los generadores de
Alphard
[SWL-77].
Binder.pas no es efectivo.
Binder.pas contenedores que no pueden ser
parametrizados con los esquemas de parametrización usados
en la actualidad.
Binder.pas no pueden ser declarados como registros
Pascal, usando la palabra reservada "RECORD".
OBJECT, el orden de los
argumentos con que hay que invocar sus métodos es diferente
al requerido para invocar una rutina que usa variables declaradas
como RECORD. Por ejemplo, el método
TObj.Less(x) debe reprogramarse como la
función Less(x, TObj) si
TObj estuviera definido con la palabra
RECORD, y no con OBJECT. O sea que, si
en un programa se cambia RECORD por
OBJECT, Less() pasa a calcular el valor
de Greater() sin que el programador se dé
cuenta.
Binder.pas,
de forma que al invocar TBinder.Define() se agregue
un parámetro más que indique si un tipo ha sido
definido como OBJECT o como RECORD. En
realidad es relativamente sencillo agregarle a
Binder.pas soporte para registros, pero no se hizo,
pues el método TBinder.Define()ya tiene
muchos argumentos, y agregarle otros para este caso especial
complica las cosas más de lo que las mejora, (ver
Figura 7.7).
OBJECT, lo que además ayuda a que el
programa pueda ser extendido con mayor facilidad. Todos los
lenguajes modernos ya tienen soporte para
OOP, y Pascal no es la
excepción. Además, cualquier cualidad que tenga
una variable declarada como RECORD, también
la tendrá si se la declara como OBJECT, por
lo que esta limitación en realidad no lo es.Binder.pas sirven solamente para examinar el contenido del
contenedor (modo de solo lectura: read-only).
A[i]. Es más claro usar
verbos como Insert(), Append() y
Remove() que instrucciones de asignación del
tipo C = e;, que además tienen el
inconveniente de que sesgan la opinión del programador
para que crea que, para meter un valor en un contenedor, siempre
hay que copiarlo. Es cuestionable que este estilo de
programación sea lo más adecuado en una biblioteca
de uso general. Más aún, esto hace más
complicada la biblioteca.
C.LinkAt(p,e.lnk) para usar
contenedores.CTPinst
para obtener una unidad Turbo Pascal independiente, que sirva
como caparazón para accesar el contenedor, sin sacrificar
la verificación fuerte de tipos. El costo es
mínimo, pues sólo hace falta invocar una función
intermedia.
TYPECAST, que permita
convertir eficientemente un puntero al campo de enlace en un
puntero al elemento o viceversa, sin eliminar la
verificación fuerte de tipos.CTPinst es necesario
que cada
ADT elemental esté
definido en una unidad (aunque no tiene que existir necesariamente
una unidad diferente para cada elemento). Esto quiere decir que no
se puede usar CTPinst para aquellos ADT's elementales
definidos en el programa principal. La razón de que esto
ocurra es que la unidad de envoltorio, usualmente llamada
Envelope.pas, debe
tener acceso a la definición del elemento, y esto sólo se
puede lograr si ese elemento ha sido definido en una unidad, no en
el programa principal. Por eso en la cláusula
USES de la unidad Envelope.pas siempre
aparece el nombre de la unidad que contiene el elemento.
CTPinst para corregir esta pequeña
incomodidad. Además, es una saludable práctica que
el programador ponga en módulos diferentes los objetos
que son diferentes. En algunos casos esto incrementa levemente
el número de archivos que conforman un programa, aunque
en muy pocas ocasiones es necesario minimizar la cantidad de
archivos que contienen los módulos de un sistema.
De todas formas, el que dos objetos residan en el mismo archivo
no implica que la cantidad de módulos del programa
disminuya.C.UnLink(pE), que
desliga del contenedor C el elemento
pE^, la operación C.Value(px)
debe verificar que la posición "px" en el
contenedor C no sea NIL. De lo contrario
puede ocurrir que, al tratar de convertir el puntero
"px" en un puntero al elemento, el puntero nulo
NIL sea derreferenciado, lo que puede resultar en un
error fatal en tiempo de ejecución. Siempre que se ejecute
esta sección de código
se requiere que px<>NIL:
pE := Binder.Link_to_PObj( px );C.Value(): PElem de la siguiente forma:
IF p<> NIL THEN BEGIN Value := PElem( Binder.Link_to_PObj(px^) ); END ELSE BEGIN Value := NIL; END;
C.Remove(pos) para
eliminar el elemento que está en la posición
"pos" del contenedor "C", pero, si se
usan los métodos de parametrización que ofrece
Binder.pas, esta operación debe ser sustituida
por C.UnLink(pos, pl), en donde
"pl" es un puntero al campo de enlace del elemento
que ha sido removido del contenedor "C". En
particular, esto quiere decir que si se usa
Binder.pas, el programador cliente del contenedor
tiene la responsabilidad de destruir el elemento removido,
invocando la operación de destrucción usando el
puntero de ligamen "pl" retornado por
UnLink(), mientras que en los contenedores
tradicionales esa responsabilidad no existe, pues la
operación de borrado del elemento está encapsulada
dentro de la implementación del contenedor.
Container.Delete(pos, binder) que,
además de desligar el nodo, también lo destruya,
como se muestra, por ejemplo, en la
Figura 7.34. Desde esta
perspectiva, la operación Container.UnLink()
es de menor nivel, pues Delete(pos) la invoca.
Binder.pas, el
programador cliente debe
crear primero una instancia, la que luego puede enlazar al
contenedor. Si se usa cualquier otra biblioteca de contenedores
parametrizables, lo usual es que exista una operación
Container.Insert(), que
simplemente deja una copia del valor insertado en el contenedor:
la responsabilidad de crear el nuevo nodo a insertar recae en el
programador del contenedor, lo que simplifica el uso de la
biblioteca.
Elem.Copy() y
Elem.Move(), pese a que
es más eficiente usar, al menos, la operación
Elem.Swap() para dejar
valores dentro del contenedor (eso se discute en la
sección 4.8 y en
[HW-91]). Por el contrario, si
el programador cliente usa un contenedor parametrizado por medio
de
Binder.pas, tiene la oportunidad de construir el
valor que efectivamente será insertado en el contenedor,
y luego no tiene que pagar el precio de copiarlo cuando lo
agrega. Esto le da más control al programador cliente,
quien puede aprovecharlo para aumentar la eficiencia de sus
programas.
CTPinst, para agregarle operaciones al
contenedor de forma que tenga una que permita crear elementos
con facilidad, como se hizo en el caso de la lista con
List.ctp.
Elem.Copy() o Elem.Move().TElement como una variable local y luego la enlaza en
un contenedor, cuando la rutina retorna quedará almacenado
un valor inválido en el contenedor, pues esa variable local
ya ha dejado de existir por que la memoria que ocupa es recuperada
de la pila de ejecución del programa cuando retorna de la
subrutina.
PROCEDURE Al_Chanfle({?} VAR C: TContainer);
VAR
e : TElement;
BEGIN
C.LinkAfter(Container.Null, e.link);
{ "e" deja de existir al retornar Al_Chanfle() }
{ "C" contiene un valor inválido }
END; { Al_Chanfle }
Binder.pas son más eficientes que otros,
y le brindan mayor control al programador cliente, y eso lo
obliga a actuar con mayor responsabilidad al usar la biblioteca
de contenedores parametrizables.
Binder.pas, es posible que todas las instancias de
los elementos de un contenedor existan en la pila de
ejecución del programa, o en memoria estática, lo
que no puede lograrse al usar otro tipo de contenedores que
siempre almacenan sus valores en
memoria dinámica. En
algunos ambientes, como, por ejemplo, cuando se implementan
programas que no pueden usar memoria dinámica para
sistemas operativos o sistemas de Tiempo real
(Embedded systems en inglés), esto limita
severamente al programador, quien no puede usar las bibliotecas
de contenedores disponibles.
TLnode por un vector de punteros sin cambiar la
implementación de Tree.pas.
Binder.pas.Binder.pas necesita es que cada objeto tenga
un constructor y un destructor sin parámetros; esto en
manera alguna le impide al programador definir otros más
si eso le facilita su labor. Esta limitación es similar
a la que impone C++ cuando se usa un vector de elementos, pues
obliga a que cada elemento pueda ser inicializado con su
constructor sin argumentos.Binder.pas, en donde
se usa bastante este recurso. Además, esa
implementación no es portable, pues sólo funciona para la
plataforma de 16 bits de DOS v6.20.
Clone() para duplicar
el valor de un objeto. Por lo demás, vale la pena
implementar en C++ todos los contenedores parametrizables, por
lo que, cuando se trabaje en eso, habrá que tomar en
cuenta este detalle, y muchos otros. Lo importante es que toda
la
tecnología que representa
Binder.pas se puede implementar cumpliendo con
todos los requerimientos definidos en la
sección 8.2.TBinder.Define(), el
programador olvida definir alguna de las operaciones importantes
de su elemento, como se hace para el tipo TcharL en
la
Figura 7.11, puede ocurrirle que
la operación por defecto que Binder.pas le
provea no sea la adecuada, lo que deja en su programa un error que
luego será muy difícil de encontrar.
Binder.pas, sino al usar
cualquier tipo de objeto. La mejor forma de prevenir este
problema es educar al programador para que sepa cuándo es
necesario que defina alguna de las operaciones básicas
para sus objetos y, en particular, es importante advertirle que
la mayoría de los objetos que no son simples necesitan de
una operación de copia especial. Precisamente por eso, en
C++ la operación de copia que por defecto usa el
compilador no es una copia bit por bit, sino una copia en que se
invoca el operador de copia de cada uno de los campos del
objeto.inline" de C++.Iterator.Bind() e
Iterator.BindB() (con
B), pues el segundo debe usarse
cuando el orden de recorrido del iterador depende del valor de los
objetos [como Elem.Less()]. Este es un detalle
difícil de recordar.
Iterator.Bind() para que invoque
siempre a Iterator.BindB(),
aunque, conceptualmente, esto crea una incoherencia.
Binder.pas no es la excepción. No se
puede hacer chocolate sin cacao.TBinder.Define() para cada
elemento, pues tiene demasiados argumentos.
CTPinst. Otra solución es crear
un grupo de unidades que tengan varios procedimientos que ayuden
a invocar TBinder.Define(). Con la experiencia
que se gane al usar Binder.pas, poco a poco se
definirán cuáles módulos de apoyo conviene
implementar.TBinder.Define(), pues lo que le pasa a
uno en la práctica es que uno pone los constructores y
destructores en el lugar en que van los procedimientos
Init() / Done() que no son
virtuales. Es difícil e
incómodo recordar cuál es cuál entre los
parámetros
Binder.Define(... type_of, p_cnstrc, p_dstrc, p_init, p_done ...).
CTPinst para aliviar este
inconveniente. Es más, si lo desea puede usar
directamente el ligador que CTPinst define, sin
usar las operaciones incluidas en el resto de la unidad
Envelope.pas.Binder.pas
para levantar esta limitación, pero eso sería
propiciar malas prácticas de
programación.TElement que vaya a estar
enlazado en un contenedor, es obligación del programador
cliente del contenedor inicializar el campo de enlace
".link" que pertenece al contenedor. O sea, siempre
hay que inicializar element.link.
NIL en un nodo
indique que no hay descendencia.
element.link.
Binder.pas, o la de los contenedores, para levantar
esta limitación, pero eso sería incorrecto, pues
es una mala práctica de programación no definir
destructores para cualquier tipo. Nunca ayuda el propiciar
prácticas que puedan llevar al error.CTPinst. Como lo usual es que en un
mismo programa haya pocas instancias de contenedores, aunque
puede haber muchos elementos, el impacto de esta
limitación no es tan significativo, aunque puede ocurrir
que un programador escoja usar un contenedor, por ejemplo, la
lista, para implementar otro, por ejemplo, el árbol.
TContLnk,
que es el tipo genérico definido en la unidad
Binder.pas, para
evitar que se use una posición definida para un contenedor,
por ejemplo TLlink (con
L) para la lista, en un lugar en donde se necesita un
posición a otro contenedor, por ejemplo
TTlink (con T) para el
árbol. La verificación de tipos que se logra de esta
manera no es muy completa, pues siempre es posible que el
programador cliente por
equivocación use la posición en una lista, por
ejemplo de caracteres, como si fuera una posición en otro
tipo de lista, de personas, pues ambas listas usan el mismo tipo
de campo de enlace, y por lo tanto usan el mismo tipo de
posición en el contenedor: PLlink. Por eso es
necesaria la incomodidad de definir el tipo Iterator
en el módulo del contenedor
(List.pas,
Tree.pas,
Vector.pas) y no en
Binder.pas, aunque a fin de cuentas no se logre una
verificación fuerte de tipos completa.
CTPinst para proteger con verificación
fuerte de tipos no solo el contenedor, sino también a
todos sus iteradores. Para lograrlo se puede crear una plantilla
para cada iterador
(InOut.ctp para
InOut.pas,
BackL.ctp para
BackL.pas), o se
puede también agregar la declaración del iterador
en el archivo de plantilla del contenedor
(en List.ctp para
List.pas,
etc.).Binder.pas no se usa la
verificación fuerte de tipos del compilador, es posible
tener dentro del mismo contenedor objetos de tipos diferentes. Por
ejemplo, en una pila de enteros se pueden enlazar también
números reales. Por eso el programador debe ser muy
cuidadoso al usar ADT's parametrizados con
Binder.pas.
CTPinst. Además esto puede
verse no como una desventaja, sino más bien como una
cualidad, pues en algunas ocasiones conviene mezclar objetos
diferentes dentro del mismo contenedor: esta es una de las
cualidades de la Programación Orientada a los
Objetos.Binder.pas ofrece. Simplemente son alternativas que
el programador debe evaluar al escribir su programa, de cara a
la eficiencia o a otros criterios que sean relevantes.
Hubo una época en el desarrollo de la computación en la que el costo más alto de cualquier aplicación era la inversión en equipo. Sin embargo, ahora lo más caro es el personal humano, que cada vez es más especializado. En este contexto cabe preguntarse si la eficiencia de un algoritmo es todavía importante. La respuesta, por supuesto, es obvia: la eficiencia de los algoritmos nunca dejará de ser importante.
Para lograr que este trabajo esté completo, también
se ha examinado el costo de parametrizar contenedores por medio de
Binder.pas. Las primeras pruebas se corrieron en un
computador con las siguientes características:
Esas pruebas se corrieron bajo el sistema operativo DOS v6.20 porque es un sistema operativo monousuario, que nunca le quita control al programa que se está ejecutando. Para evitar que pequeñas variaciones de ambiente influyeran en los resultados, cada prueba se corrió miles de veces y, en todos los casos, el computador estuvo dedicado exclusivamente a correr las pruebas, sin interferencia de otros programas. A fin de cuentas se obtuvo un tiempo total de corrida, con base en el cual se han sacado las conclusiones que más adelante se discuten sobre el rendimiento de los algoritmos.
Al revisar los resultados obtenidos en las primeras pruebas fue
obvio que algunas mediciones estaban mal hechas, y que el contexto
en que se ejecutaban los programas debía ser muy simple,
para evitar cambios en los tiempos de ejecución. Fue
necesario diseñar una metodología que permite
repetir el experimento. El programa usado para medir los tiempos
de ejecución es
bndrbnch.pas, que se
recompila en cada ocasión invocando el archivo de comandos
BENCH.bat. Se
continuó usando el sistema operativo DOS, pero se le
eliminaron de los archivos
CONFIG.sys y
AUTOEXEC.bat todos
los programas residentes que pudieran interferir con el
desempeño de la máquina. En particular, se
eliminaron los programas SmartDrive (que acelera el
acceso a los discos) y DosKey (que permite editar en
la línea de comandos), pues ambos roban ciclos de
procesador asincrónicamente. El computador utilizado en
esta nueva ronda de pruebas fue el siguiente:
Al correr estas pruebas surgió otro problema. Como el procesador Pentium es muy rápido, para listas pequeñas el tiempo total de ejecución era cero, pese a que las pruebas se repitieron 2,000 veces para cada lista. Fue necesario repetir de nuevo todo el experimento, pero aumentando a 50,000 veces las repeticiones para listas cortas, de hasta 450 elementos, y hasta 10,000 iteraciones para listas de hasta 900 elementos. Para las listas más grandes, cada ciclo de pruebas se ejecutó, de nuevo, 2,000 veces.
Es difícil determinar si una forma de programación
es mejor que otra porque no se puede predecir en cuál
contexto será usada una u otra. Ante esta dificultad, para
cuantificar el costo de usar Binder.pas se ha seguido
la ruta más simple, usando el contenedor más famoso:
la lista. Por eso, lo que se ha cuantificado es el tiempo que se
tarda procesando una lista implementada usando el estilo de
programación de Binder.pas, para compararlo
con lo que se tarda si se usa una lista común, no
parametrizable. Para evitar sesgar los resultados, se ha usado un
generador de números aleatorios cuya semilla inicial es
igual en todos los casos.
El procesador Pentium tiene acceso de 32 bits a su memoria,
pero como el compilador usado fue Turbo Pascal
versión 7.0, todos los programas objetos accesan la
memoria utilizando instrucciones de 16 bits. Esto presenta un
problema, pues el criterio para alinear datos en palabras de
16 bits, que es el que se obtiene con la directiva de
compilación {A+} usada en todas las pruebas,
no alinea en frontera de palabra de 32 bits, que es lo
óptimo para el procesador Pentium, lo que también
afecta los tiempos de ejecución. Por eso es posible que al
repetir las pruebas en otros ambientes, las estadísticas
varíen respecto de las recolectadas en esta plataforma,
aunque la relación de eficiencia en cada prueba debe
mantenerse constante. Por ejemplo, puede ocurrir que los tiempos
de ejecución de la lista de enteros varíen respecto
de los de la lista de hileras, pero la razón entre los
tiempos de ejecución de un mismo tipo de lista, enteros vs.
enteros, no debe variar significativamente.
|
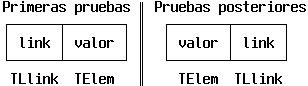
TElem.link
En las primeras pruebas de rendimiento, el campo de enlace del
contenedor era el primer campo del objeto, como se muestra en la
parte izquierda de la
Figura 8.7, pero luego fue
trasladado después del valor del elemento. Esto se hizo
para que al transformar un puntero al campo de enlace, de tipo
^TLlink, en un puntero
al elemento, de tipo ^TElem, haya que ajustar el
valor del puntero para que apunte al principio del elemento
(quitándole la distancia a que se encuentra el campo de
enlace del principio del elemento), de manera que esa
operación quedara reflejada en los tiempos de
ejecución de los programas. En caso contrario, para
transformar un puntero al campo de enlace en el puntero al
elemento basta usar una transferencia de tipos
(typecast), que siempre tiene costo nulo en tiempo de
ejecución.
Se forzó, en algunos casos, que el
campo de enlace "link"
de la lista quedara desalineado de frontera de palabra. Por eso se
corrieron pruebas con dos tipos de listas de hileras, unas que
ocupan una cantidad de bytes divisible por cuatro, y otras que
siempre dejan desalineado el campo de enlace de la lista. Cuando
el valor del nodo de la lista es CHAR, que siempre
ocupa un byte de memoria, aun si se usa la directiva de
compilación {$A+}, el campo de enlace
quedará desalineado, pues queda almacenado un byte
después del valor.
PROCEDURE Copy_LstB(
{?} VAR L : TListB;
{?} VAR Lcp : TListB;
{+} cycles: WORD; { cuántas veces }
{+} seed : LONGINT; { # aleatorio }
{-} VAR lap : LONGINT { duración total }
);
{ RESULTADO
Copia "cycles" veces a lista "L" sobre "Lcp",
y calcula el tiempo "lap" que ha transcurrido. }
|
TListB
En la Figura 8.8 está el
encabezado del procedimiento
Copy_LstB() que se encarga de
ejercitar las operaciones de la lista. Las operaciones que se han
cuantificado sobre la lista son simples: copiar la lista y
eliminarle elementos en orden aleatorio. El tiempo total
registrado es el requerido para realizar estas operaciones varias
veces, de acuerdo con el valor de la variable
"cycles". Los valores de la lista "L",
que es copiada sobre "Lcp", son generados usando un
generador de números aleatorios, cuya semilla es
"seed".
Hay varias razones por las que conviene usar un procedimiento de
copia de listas como Copy_LstB() para medir el
rendimiento de los contenedores implementados con el apoyo de
Binder.pas:
Brand.pas basado en
el que
Borland International
incluye con su compilador de C++ v3.1.
/* rand.c Copyright (c) 1987, 1991 by Borland Int. */
#define MULTIPLIER 0x015a4e35L /* 22,695,477 */
#define INCREMENT 1
static long Seed = 1;
void srand(unsigned seed) {
Seed = seed;
}
int rand(void) {
Seed = MULTIPLIER * Seed + INCREMENT;
return((int)(Seed >> 16) & 0x7fff);
}
/* rand.c End of file */
|
rand() de Borland C++ v3.1El generador de números aleatorios de 16 bits de la Figura 8.9 es simple, y ha sido usado por muchos programadores, pese a que no es lo mejor que existe. Lo que importa es que produce listas cuyos valores no son todos consecutivos.
VAR
px: PLlink;
i,count: WORD;
rand : TBRand ;
chrono: TTimer;
BEGIN { Copy_LstB }
rand.Init; rand.Seed(seed);
chrono.Init;
FOR i := 1 TO cycles DO BEGIN
Lcp.Copy(L);
IF NOT Lcp.Equal(L) THEN BEGIN
WriteLn('ERROR: Copy_LstB(Lcp <> L)');
END;
count := L.Count;
px := Lcp.LPos(rand.Rand MOD count);
WHILE NOT Lcp.Empty DO BEGIN
px := Lcp.LPos(rand.Rand MOD count);
Lcp.DeleteAfter(px);
DEC(count);
END;
Lcp.Delete_All;
END;
lap := chrono.Lap;
rand.Done; chrono.Done;
END; { Copy_LstB }
|
Copy_LstB()
La Figura 8.10 es la
implementación del procedimiento Copy_LstB(),
especificado en la
Figura 8.8. Este código es
el adecuado para una lista que incluye un puntero al contenedor,
de tipo TListB (con
B).
El proceso que se aplica a cada lista es el siguiente: Primero la
lista original entra en el argumento "L", y de
ahí es copiado a "Lcp". El generador de
números aleatorios es la variable "rand", de
tipo TBRand, definido en la unidad
BRand.pas. Luego se
genera un nuevo número aleatorio invocando a
rand.Rand() y luego se elimina el elemento de la
lista que está en esa posición. Se continúa
hasta que ya no queden elementos en la lista. La variable
"chrono" sirve para calcular la cantidad de tiempo
que ha transcurrido; es de tipo TTimer, definido en
la unidad
SFCtimer.pas. La
cantidad de tiempo transcurrido se mide en las unidades de reloj
que el procedimiento Pascal DOS.GetTime() retorna;
este es el valor que queda guardado en la variable
"lap".
PROCEDURE Copy_LstK(
{?} VAR L : TList;
{?} VAR Lcp : TList;
{+} cycles : WORD; { cuántas veces }
{+} seed : LONGINT; { # aleatorio }
{-} VAR lap : LONGINT; { duración total }
{+} VAR Element: TBinder { ligador }
);
VAR
px : PLlink;
i,count: WORD;
rand : TBRand ;
chrono: TTimer;
BEGIN { Copy_LstK }
rand.Init; rand.Seed(seed);
chrono.Init;
FOR i := 1 TO cycles DO BEGIN
Lcp.Copy(L, Element);
IF NOT Lcp.Equal(L, Element) THEN BEGIN
WriteLn('ERROR: Copy_LstK(Lcp <> L)');
END;
count := L.Count;
px := Lcp.LPos(rand.Rand MOD count);
WHILE NOT Lcp.Empty DO BEGIN
px := Lcp.LPos(rand.Rand MOD count);
Lcp.UnlinkAfter(px, px);
Element.Discard(px);
DEC(count);
END;
Lcp.Delete_All(Element);
END;
lap := chrono.Lap;
rand.Done; chrono.Done;
END; { Copy_LstK }
|
Copy_LstK()
Para el procedimiento Copy_LstB(), en la
Figura 8.10, se invoca la
operación
TListB.DeleteAfter(px) porque, como
la lista Lcp es de tipo
TListB (con
B), tiene un
ligador asociado,
Lcp.Bound^, por medio del cual se invoca la
operación TBinder.Discard() para eliminar el
elemento recién desligado de la lista. Si se usa una lista
que no tenga asociado un ligador, de tipo TList (sin
la B), hay que desligar el elemento
invocando TList.UnlinkAfter(), para luego destruirlo
usando TBinder.Discard():
Lcp.UnlinkAfter(px, px);
Element.Discard(px);
Esto se muestra en la
Figura 8.11 en donde
está el procedimiento
Copy_LstK() completo. El encabezado de este
procedimiento tiene un argumento más que el de
Copy_LstB(): el
ligador de tipo
TBinder, llamado en este caso "Element".
Por eso, para destruir el elemento recién desligado de la
lista con Lcp.UnlinkAfter(px, px), se invoca
Element.Discard(px) pasando como argumento la
posición "px",
de tipo ^TLlink, que es un
puntero al
campo de enlace de la lista.
El tiempo total de corrida de las pruebas asciende a varios meses,
pues algunas pruebas tomaron mucho tiempo. Por ejemplo, insertar y
borrar en una lista de dos elementos de tipo CHAR,
toma un par de segundos, pero se necesitan horas si la lista tiene
5,000 elementos, y cada uno de ellos es una hilera de 255
caracteres. Cuando se corrieron las pruebas, el computador
tardó noches enteras corriendo las distintas versiones del
mismo algoritmo: unas usaban el contenedor lista implementado
directamente, y otras usaban la lista genérica
parametrizada a través de Binder.pas.
UNIT Etst;
{$IFDEF Etst_INTEGER}
TYPE
Etst_TYPE = INTEGER;
CONST
SizeOf_TEtst = SizeOf(Etst_TYPE);
TEtstName = 'INTEGER';
{$DEFINE Use_INTEGER}
{$ENDIF}
TYPE
TEtst = OBJECT (Binder.TObj)
_val : Etst_TYPE;
PROCEDURE Init;
PROCEDURE Done;
END;
|
_val en
Etst.pas
Para determinar si el tipo de datos contenido en la lista afecta
los resultados, se usaron varios tipos de datos en las pruebas.
Para eso fue necesario crear un mecanismo que permitiera crear
listas que en un caso contendrían elementos de tipo entero,
en otro, elementos reales o hileras. Para evitar usar varios
programas diferentes para cada tipo de datos se usó la
unidad
Etst.pas en donde se
define el tipo TEtst, que es el tipo de dato
almacenado en la lista. De esta forma, para que la lista
ejercitada por el programa bndrbnch.pas fuera una
lista de números enteros, se definió el campo
"_val" de TEtst como un
campo de tipo entero, pero para hacer las pruebas con listas de
números reales se definió
"_val" como un campo real. Por eso
la unidad Etst.pas contiene varias directivas de
compilación condicional que sirven para recompilar el
programa
bndrbnch.pas. En la
Figura 8.12 se muestra el
segmento de código en que se define el tipo del campo
"_val" como un campo entero, siempre
y cuando la variable de compilación condicional
"Etst_INTEGER" esté definida.
{ S6-1000.bch }
CONST Bench_File = 'S6-1000';
CONST List_Length = 1000;
CONST Random_Seed = 11111;
CONST STRING_size = 64; { = 2^6 }
{$DEFINE Etst_STRING}
|
S6-1000.bch
En el archivo de comandos
BENCH.bat se invoca el
compilador de Turbo Pascal para recompilar
bndrbnch.pas, pero
usando un archivo "*.bch" diferente. Cada archivo
"*.bch" representa una lista diferente, tanto por la
cantidad de elementos que tiene, como por el tipo de datos de cada
elemento. Por ejemplo, el archivo LL-2000.bch
representa una lista de dos mil enteros largos; la letra
"L" en el nombre del archivo indica cuál tipo
de datos contiene la lista
(L=LONGINT). El archivo
S6-1000.bch que se muestra en la
Figura 8.13 define una corrida de
bndrbnch.pas, en donde se usa una lista de hileras de
1,000 elementos, que es el número que aparece en el nombre
del archivo. La letra "S" al principio del nombre del
archivo indica que, en la corrida, los elementos de la lista
serán hileras, de tipo
STRING; el tamaño de cada
hilera es de 64 bytes, pues 64 = 2^6, lo
que efectivamente implica que la hilera tiene capacidad para
63 = 64-1 caracteres. El valor
"6" es el dígito que está en el nombre
del archivo: S6.
{ Z6-1000.bch }
CONST Bench_File = 'Z6-1000';
CONST List_Length = 1000;
CONST Random_Seed = 11111;
CONST STRING_size = 64-1; { = 2^6 }
{$DEFINE Etst_STRING}
|
Z6-1000.bch
Si se hubiera compilado
bndrbnch.pas usando
el archivo z6-1000.bch (con una
"Z" en lugar de una
"S", como se muestra en la
Figura 8.14), se obtendría
una lista que tiene un byte menos de tamaño en el campo del
elemento, para forzar a que el
campo de enlace de la lista no quede
alineado en frontera de palabra.
Cada archivo "*.bch" representa una
combinación tipo-longitud diferente, y en cada archivo
"*.bch" está el código Pascal necesario
para que, al compilar el programa
bndrbnch.pas, el
tipo del campo "_val" de TEtst, definido
en la unidad
Etst.pas, sea el que
corresponde al nombre del archivo "*.bch". Los
archivos "*.bch" deben ser generados con anterioridad
a la corrida de
BENCH.bat, y son
archivos diseñados para ser incluidos con la directiva del
compilador Pascal {$I Bench.inc}, para que
completen la implementación de la unidad
Etst.pas. Todos los archivos "*.bch" son
parecidos, y contienen código Pascal similar al del archivo
S6-1000.bch de la
Figura 8.13.
{$IFDEF Run_Batch}
{$I Bench.inc}
{$ELSE}
CONST Bench_File = 'Warp';
CONST STRING_size = 255 DIV 127;
CONST List_Length = 500;
CONST Random_Seed = 11111;
{$DEFINE Etst_EXTENDED}
{$ENDIF}
|
Bench.inc en
Etst.pas
En cada corrida de
BENCH.bat se usa la
opción -DRun_Batch para que
al recompilar el programa
bndrbnch.pas se use
un archivo "*.bch" diferente. Para lograr esto, en
BENCH.bat se usa el siguiente llamado recursivo:
for %%d in (*.bch) do call BENCH.bat +++ %%d
El primer argumento contiene +++ para distinguir la
invocación inicial a BENCH.bat de los llamados
recursivos. Si el siguiente archivo "*.bch" que se va
a procesar en el ciclo for es el archivo llamado
"S6-1000.bch", en BENCH.bat
copiará este archivo sobre Bench.inc, que es
el archivo que se incluye, usando
{$I Bench.inc}, en la unidad
Etst.pas, como se muestra en la
Figura 8.15. Por eso en
BENCH.bat aparece el siguiente comando:
copy %2 BENCH.inc
En cada invocación recursiva de BENCH.bat, el
segundo argumento %2 se reemplaza por alguno de los
archivos "*.bch". Por eso, eventualmente ese
argumento tendrá el valor
"S6-1000.bch", por lo que el
comando ejecutado en BENCH.bat será:
copy S6-1000.bch Bench.inc
El último renglón de cada archivo
"*.bch" es muy importante, como puede verse en el
caso de
S6-1000.bch en la
Figura 8.13, pues es el que
define la variable de compilación Etst_STRING.
De esta forma, al compilar la unidad
Etst.pas, el tipo del
campo "_val" del tipo TEtst es
STRING[64-1]: en esa corrida de
bndrbnch.pas, el
tipo
Etst.Etst_TYPE queda
definido como STRING[63] gracias a la
compilación condicional.
TYPE
PEtstL = ^TEtstL;
TEtstL = OBJECT (TEtst)
link : List.TLlink;
PROCEDURE Init;
PROCEDURE Done;
END;
|
TEtstL
El tipo TEtst de la
Figura 8.12 solamente contiene un
campo, llamado "_val". Para almacenar elementos de
tipo TEtst en las listas parametrizadas con
Binder.pas, es
necesario agregarle un campo de enlace de tipo
List.TLlink. Esto se logra al definir un nuevo tipo
derivado de TEtst, llamado
TEtstL (con la
"L" de Lista), como
se muestra en la
Figura 8.16. Al definir el tipo
TEtstL también conviene definir
PEtstL, que es un puntero al elemento de la lista.
Estos punteros no apuntan al campo de enlace (link),
pues no son de tipo List.PLlink.
Todas las ideas descritas anteriormente sirven para lograr usar el
mismo programa,
bndrbnch.pas, para
correr el mismo algoritmo en diferentes implementaciones del ADT
lista. El uso de una lista parametrizable en Pascal no es tan
complicado, pero el que sea posible implementar un programa como
bndrbnch.pas es muestra de que efectivamente es
posible parametrizar contenedores en Pascal, compartiendo la
implementación de los algoritmos. Para terminar la
descripción de cómo fueron obtenidas las mediciones
de tiempo de ejecución, falta describir los diferentes
tipos de lista que fueron usados. En total se usaron cuatro tipos
de lista diferentes, y a cada uno de ellos corresponde un
procedimiento de copiar la lista; en la
Figura 8.8 está el que
corresponde a TListB, y en la
Figura 8.11 el de
TList. Esta es la descripción detallada de los
diferentes tipos de listas usados para comparar los tiempos de
ejecución:
TLstCLstC.pas, y requiere
que el programador cliente escriba una unidad
Elem.pas que
implemente cada una de las
operaciones elementales que
se usan en la implementación de LstC.pas.
Para usar dos de estas listas, el
programador cliente debe
copiar manualmente la implementación completa de la
unidad LstC.pas, efectivamente
instanciando a mano sus
listas.TListList.pas, por lo que
para accesar el elemento de la lista hay que contar, de
antemano, con el
ligador que lo describe. Esta
lista es la que corresponde al procedimiento
Copy_LstK() de la
Figura 8.11, en donde se usa
el ligador "Element" para manipular los valores
almacenados en la lista, que el procedimiento recibe como un
argumento extra.TeList_TEtstL_linkCTPinst al elemento TEtstL definido
en la unidad
Etst.pas, para
generar una interfaz para la lista con base en la plantilla que
está en el archivo
List.ctp, interfaz
que CTPinst dejó en la unidad
Envelope.pas.
Todas las operaciones de esta lista siempre reciben punteros a
los elementos como argumentos (de tipo
PEtstL), por lo que para el
programador cliente estas
listas se usan de forma similar a una lista de tipo
TLstC. En otras palabras, en esta lista una
"posición" en la lista es
simplemente un
puntero al elemento que
está almacenado en la lista. La única diferencia
entre esta lista y una definida con el módulo
LstC.pas es que el
programador cliente tiene la responsabilidad de incluir un
campo de enlace en su
elemento (si no lo hiciera,
el código generado en la unidad
Envelope.pas por CTPinst no
compilaría con el resto del programa). En otras
palabras, el programador cliente debe usar elementos de tipo
TEtstL (con
L), en lugar del tipo
TEtst que se usa en una lista TLstC.
TeList_TEtstL_link tienen que
invocar las operaciones del elemento a través de un
ligador definido como variable
global en la unidad
Envelope.pas, es
natural esperar que estas listas sean un poco menos eficientes
en tiempo de ejecución que las listas de tipo
TLstC, que accesan directamente las operaciones
del ADT
elemental almacenado. Por
ejemplo, para comparar dos listas se usa esta
invocación:
TeList_TEtstL_link.Equal(o);
TList.Equal(o, Binder_TList_TEtstL_link);
Binder_TList_TEtstL_link
es el ligador definido en Envelope.pas
como variable global para que sea compartido por todas las
listas. Más aún, las operaciones de estas listas
necesitan ajustar los punteros usando el ligador antes de
invocar las operaciones de TList, que es donde
se hace efectivamente todo el trabajo algorítmico de la
lista. Por ejemplo, como se muestra en la
Figura 7.32, la
invocación a:
TeList_TEtstL_link.LinkAfter(p, x); { con "e" }
TList.LinkAfter(@ (p^.link), x.link);
LstC.pas, tienen la
gran ventaja de que todas comparten la misma
implementación de la lista, lo que disminuye el
tamaño de los programas si se usan varias listas
diferentes.TListB Binder.pas, pero
sin usar el programa CTPinst para lograr
verificación fuerte
de tipos. El camino seguido incluye usar la unidad
Bound.pas en la
implementación de la unidad
ListB.pas. Estas
listas incluyen un puntero al
ligador que describe el
elemento que contienen, el que se puede obtener invocando
cualquiera de las operaciones
TListB.Element() o
TListB.Bound() (ver
Figura 7.39). Para estas
listas no hay que
instanciar plantilla
alguna con CTPinst, pero a cambio hay que usar un
poco más de espacio en cada lista (para almacenar el
puntero al ligador). Para esta lista el compilador no verifica
que los tipos de los elementos sean los correctos, pues se usa
directamente el método
TList.UnLinkAfter(x.link) para enlazar el
campo de enlace
".link" a la lista.
{$IFDEF INSTANTIATE} {$IFNDEF INSTANTIATE}
TYPE
List{.ctp} = TEMPLATE (TList)
INSTANTIATE <TElem> TO TEtstL;
INSTANTIATE <PElem> TO PEtstL;
INSTANTIATE <link> TO link;
USES Init; TO Less USES IsLess;
USES Done; USES Equal;
END; { List } {$ENDIF} {$ENDIF}
|
List.ctp para definir
Etst.TEtstL
En la Figura 8.17 se muestran las
declaraciones que están en la unidad
Etst.pas y que son
usadas por el programa CTPinst para instanciar las
listas de acuerdo con el archivo de plantillas
List.ctp (todo el
código Pascal generado por CTPinst queda en la
unidad
Envelope.pas). Como
en la plantilla List.ctp el nombre de una lista se
obtiene concatenándole al identificador
"TList" el nombre del elemento, que en estos casos es
"TEtstL", y también agregando el nombre
del campo de enlace de elemento, que para el tipo
TEtstL es "link", el resultado es
que el nombre del tipo de la lista es bastante largo:
TList_TEtstL_link = TList + TEtstL + link
TeList_TEtstL_link = T+e+List + TEtstL + link
La diferencia entre TList_TEtstL_link y
TeList_TEtstL_link (con
"e") es difícil de apreciar a
primera vista, pues ambos tipos comparten una cualidad: en ninguna
instancia de esos tipos de lista se incluye un campo de tipo
^TBinder, para asociar la lista con su ligador, sino
que se usa un solo ligador para todas las listas:
Binder_TList_TEtstL_link. Una de las ventajas de usar
la plantilla List.ctp es que varias instancias de
contenedores del mismo tipo compartan el mismo ligador. La
diferencia está en el segundo tipo, cuyo nombre incluye la
letra "e" de "elemento", pues en
este caso las posiciones dentro de la lista son punteros a
elementos (^TEtstL), mientras que en el otro son
punteros a los campos de enlace (^TLlink).
En el programa
bndrbnch.pas no se
ejercitan listas de tipo TList_TEtstL_link (sin la
"e"), pues el rendimiento en tiempo
de esas listas es mejor que el de las listas
TeList_TEtstL_link, porque no hace
falta ajustar el puntero al elemento para que apunte al campo de
enlace, con la consiguiente pérdida de eficiencia en tiempo
de ejecución, como se discute en los párrafos que
siguen a la
Figura 7.32: lo que se busca
determinar con las corridas de bndrbnch.pas es
cuán ineficiente es una lista parametrizada a través
de
Binder.pas respecto de
una implementada tradicionalmente, como la lista de la unidad
LstC.pas.
UNIT Etst;
{$I Bench.inc}
{$IFDEF Etst_INTEGER}
TYPE
Etst_TYPE = INTEGER;
{$DEFINE Use_INTEGER}
{$ENDIF}
TYPE
TEtst = OBJECT (Binder.TObj)
_val : Etst_TYPE;
PROCEDURE Init;
PROCEDURE Done;
END;
|
TYPE
PEtstL = ^TEtstL;
TEtstL = OBJECT (TEtst) { con L }
link : List.TLlink;
PROCEDURE Init;
PROCEDURE Done;
END;
{$IFDEF INSTANTIATE} {$IFNDEF INSTANTIATE}
TYPE
List{.ctp} = TEMPLATE (TList)
INSTANTIATE <TElem> TO TEtstL;
INSTANTIATE <PElem> TO PEtstL;
INSTANTIATE <link> TO link;
USES Init; TO Less USES IsLess;
USES Done; USES Equal;
END; { List } {$ENDIF} {$ENDIF}
|
TEtstL definido en
la unidad
Etst.pas
La Figura 8.18 es la
combinación de las definiciones que se usan en la unidad
Etst.pas para definir el
tipo TEtstL, usado por el programa
bndrbnch.pas. Las
pruebas que se han hecho buscan comparar la velocidad con que se
puede manipular una lista tradicional, representada por el tipo
TLstC definido en la unidad
LstC.pas, con los otros
tres tipos de listas que usan ligadores de
Binder.pas. Cada uno de ellos representa un estilo
diferente de codificación:
Copy_LstC():
TLstCBinder.pas.Copy_LstK():
TListCopy_LstE():
TeList_TEtstL_linkBinder.pas, pero
requiere que el
programador cliente
utilice el generador de plantillas CTPinst, pero
le permite mantener su estilo de programación.Copy_LstB():
TListB CTPinst,
debe invocar por su cuenta TBinder.Define() y,
seguramente, en su programa utilizará este tipo de lista
que se apoya en el módulo
Bound.pas para crear
una lista que incluye un puntero a su ligador, lo que facilita
el uso de las
operaciones adicionales de
la lista (ver
Figura 7.5).
El programa
bndrbnch.pas tiene
algunas peculiaridades, pues fue diseñado para que pudiera
reiniciar ejecución automáticamente, pues en
Costa Rica a veces hay varias
fallas de fluido eléctrico durante la noche, que es cuando
en general se corrieron todas las pruebas. Además, ese
mismo programa se usó también para depurar
interactivamente varios módulos, y para generar los
archivos "*.bch".
Una implementación más eficiente de las listas
usadas en el programa
bndrbnch.pas
podría obtenerse si se usara parametrización por
herencia, como se propone en las bibliotecas del lenguaje
Oberon-2
[Mös-94]. Hasta
podría aducirse que no tiene sentido comparar los tiempos
de ejecución de listas que se usan de manera tradicional,
en donde el programador cliente nunca se preocupa de incluir un
campo de enlace en el elemento de la
lista, y se resigna siempre a que, al almacenar cada valor en el
contenedor, necesariamente se invoque a la operación de
copia
Elem.Copy(), pues la
operación de
inserción en el contenedor
siempre es mucho más eficiente si no se requiere obtener
memoria dinámica para
almacenar y copiar el valor del elemento insertado.
Sin embargo, es necesario comparar lo conocido con lo propuesto
porque si las personas no ven las ventajas y limitaciones de una
idea nueva, no la aceptarán, ni la usarán. Por eso
lo que importa al examinar las estadísticas de
ejecución es ver cuán ineficiente resulta usar la
tecnología de
Binder.pas respecto de
una implementación tradicional. Si luego la
tecnología es adoptada, será posible mejorar la
eficiencia. Pero no hay que olvidar que las comparaciones se han
hecho en el "terreno enemigo", siguiendo un paradigma de
programación contrario al de Binder.pas. Por
eso, lo que importa no es lograr la más eficiente
implementación de
bndrbnch.pas, sino comparar la velocidad de
contenedores que usan Binder.pas con lo que no lo
usan.
CONST
LogFile = 'C:\TMP\Binder.666'; { Archivo de bitácora }
TYPE
RBLog = RECORD
osVer : WORD; { versión del OS en uso [Warp, DOS] }
eType : STRING[11]; { 'EXTENDED' }
eSize : WORD; { SizeOf(Etst.TEtst) }
nSize : WORD; { SizeOf(Etst.TEtstL) }
ofsElem: WORD; { OffsetOf(TEtstL, elem) }
ofsLink: WORD; { OffsetOf(TEtstL, link) }
nCount : WORD; { # de elementos en la lista }
cycles : WORD; { # veces que se ejecuta Copy_List() }
strln : WORD; { # caracteres si eType = 'STRING[*]' }
eFile : STRING[13]; { .inc de TEtst: 'II-1000.bch' }
typeSize : STRING[11]; { name+size = 'INTEGER 2' }
lapLstC, { Duración de un ciclo para LstC }
lapLstK, { Duración de un ciclo para LstK }
lapLstE, { Duración de un ciclo para LstE }
lapLstB : LONGINT; { Duración de un ciclo para LstB }
heap : LONGINT; { cantidad de espacio usada por c/lista }
seed : LONGINT; { semilla del gen. de números aleatorios }
ranDel : WORD; { 1 si se corrió con Random_Delete }
END; { RBLog }
|
BLog.pas
Para cada vez que mediante BENCH.bat se
recompiló y corrió el programa
bndrbnch.pas, en un archivo de bitácora se
grabó el resultado de los tiempos de ejecución
obtenidos. La estructura de este archivo es la descrita en la
Figura 8.19. El archivo de
bitácora fue creciendo poco a poco, conforme nuevas pruebas
fueron completadas, hasta que a fin de cuentas se obtuvo una
versión final, que quedó almacenada en el archivo
Pascal
Binder.666. Luego este
archivo fue convertido a formato DBase, con extensión
".dbf", usando el programa CONVERT.exe
[Gut-97]. El resultado de este
proceso es el archivo
Binder.dbf, que es el
que se ha usado para producir todos los gráficos y
estadísticas que se presentan luego. El contenido de los
campos del archivo Binder.dbf es el siguiente:
osVer'DOS v6.20'.eType'STRING'
sin especificar el tamaño de la hilera. eSizeSizeOf(Etst.TEtst).nSizeSizeOf(Etst.TEtstL) (con "L"). Como el
campo de enlace de la lista sólo contiene un puntero, que ocupa
siempre cuatro bytes, se cumple siempre que:
nSize = eSize + 4ofsElemofsLinkCHAR, que tiene
un tamaño de un byte (eSize = 1),
como el campo de enlace está después del valor
almacenado en el nodo (ver
Figura 8.7), el desplazamiento
que hay que agregarle a un puntero que apunta al principio del
elemento para que apunte al campo de enlace es de un byte.
'STRING' en
que se usó un desplazamiento impar, que fuerza a que el
campo de enlace no quede alineado en frontera de palabra.nCountcycles50,000 veces; para las
medianas, de menos de 1,000 elementos, las pruebas se repitieron
10,000 veces, y para las listas grandes, de 1,000
elementos o más, las pruebas se corrieron
2,000 veces.strlneType sea 'STRING'. En caso contrario,
aquí queda un valor nulo (0).eFile.bch" que se
usó para recompilar bndrbnch.pas y correr la
prueba. typeSizeeType y eSize, pues contiene el tipo
de datos y el tamaño del valor del elemento (sin incluir
el campo de enlace). Es cómodo de usar porque siempre
tiene una longitud de once letras:
'CHAR 1,
'STRING 256', etc.lapLstCCopy_LstC(). La
unidad de medida que se usa es la que retorna el procedimiento
GetTime() del Turbo Pascal. Aunque existe un
multiplicador que permite transformar este valor en segundos,
las mediciones nunca se fueron transformadas a segundos porque
lo que interesa es comparar los tiempos relativos de
ejecución.
lapLstC. Para determinar cuán
lerdas son las listas parametrizadas con Binder.pas
respecto de la lista no polimórfica TLstC se
calculan los siguientes porcentajes:
% K = ((lapLstK / lapLstC) - 1) * 100
% E = ((lapLstE / lapLstC) - 1) * 100
% B = ((lapLstB / lapLstC) - 1) * 100
TLstC es una lista más
rápida, aunque en algunos casos ocurrió que la
lista pura TList ganó por un pequeño
margen. Puede que eso haya sido un error de medición
(tal vez cuando la prueba fue corrida el procesador Pentium
estaba "caliente"), o puede haber ocurrido que el alineamiento,
aunado al tamaño de la lista y el tamaño de la
memoria cache del procesador, haya afectado los
resultados.lapLstKCopy_lstK().lapLstECopy_lstE().lapLstBCopy_lstB().heapCopy_List() hay que almacenar dos listas,
"L" y "Lcp", en realidad esto mide el
espacio usado en esas dos listas.seed11111 (cinco unos, impar, divisible por
41 y 271).
ranDel| Tipo de lista |
Elemento Etst.pas
|
Usa a Binder.pas
|
Procedimiento |
Tiempo de ejecución |
|---|---|---|---|---|
TLstC
|
TEtst
|
NO |
Copy_LstC()
|
lapLstC
|
TList
|
TEtstL
|
SI |
Copy_LstK()
|
lapLstK
|
TeList_TEtstL_link
|
TEtstL
|
SI |
Copy_LstE()
|
lapLstE
|
TListB
|
TEtstL
|
SI |
Copy_LstB()
|
lapLstB
|
Los campos más importantes del archivo de bitácora
son los que contienen la cantidad de tiempo que tomó
procesar cada uno de los diferentes tipos de lista. Como se usaron
cuatro tipos de lista en cada prueba
(LstC,
LstK,
LstE,
LstB)
se registró en cuatro variables el tiempo total de
ejecución
(lapLstC,
lapLstK,
lapLstE,
lapLstB),
con base en los tiempos calculados por el procedimiento encargado
de ejercitar las operaciones de la lista
(Copy_LstC(),
Copy_LstK(),
Copy_LstE(),
Copy_LstB())
[ver
Figura 8.20]. Todos estos
procedimientos están definidos en el programa de prueba
bndrbnch.pas, y tienen la misma lógica,
similar a la de Copy_LstB(), cuya
implementación aparece en la
Figura 8.10.
En la Figura 8.20 se resume la
relación entre los campos almacenados en el archivo de
bitácora. El primer renglón corresponde a la lista
TlstC, que es la lista (circular) no parametrizable
con la que se contrastan las otras tres listas parametrizadas por
medio de Binder.pas. Los identificadores del tercer
renglón incluyen la letra "E"
porque las estadísticas corresponden a la lista
TeList_TEtstL_link (con
"e"). El término
"LstK" fue acuñado porque
corresponde a la lista TList, en la que se enlazan
los campos ".link" (con
"k"). El nombre
"LstB" viene de la primera letra de
la palabra "Bound", pues para la
TListB se usa la unidad
Bound.pas. Para facilitar el
uso de estas estadísticas de la tabla de la
Figura 8.20, los renglones
están en el mismo orden en que aparecen los campos que
contienen el tiempo de ejecución que tomó procesar
cada tipo de lista; este es el orden que aparece en la
definición del archivo de bitácora en la
Figura 8.19 .
La tabla de la
Figura 8.20 también resume
el menú de opciones que tiene un programador cuando usa
contenedores parametrizables. Puede programarlos de nuevo cada
vez, para obtener una lista de tipo TLstC. Puede usar
directamente Binder.pas y la lista
TlstB, pero sin disfrutar de la protección de
la verificación fuerte de tipos del compilador.
También puede usar una lista que tiene protección
por verificación fuerte de tipos, pero en donde las
posiciones son punteros sin tipo que apuntan a campos de enlace,
de tipo List.PLlink. Esta opción es
interesante porque se pueden usar los iteradores del contenedor
directamente sin enmascarar el tipo de una posición en el
contenedor (PLlink). Finalmente, el programador puede
escoger una lista en que el compilador verifica tanto el tipo de
la lista como el que denota una posición dentro de la
lista, pues ambos tipos son diferentes para cada
instanciación de la lista parametrizada. En este caso, la
protección que ofrece el compilador es máxima, pero
se paga un pequeño costo en eficiencia debido a que se hace
necesario hacer varias indirecciones al ejecutar cada
operación del contenedor. Además, también se
hace necesario enmascarar los tipos de los valores producidos por
un iterador, para transformarlos del tipo posición
genérica en el contenedor (PLlink) a un
puntero al valor almacenado en el contenedor
(PEtstL).
Type Size #(L) %K %E %B ------ ---- ----- ---- ---- ---- CHAR 1 1 41% 69% 41% CHAR 1 5 34% 58% 41% CHAR 1 10 31% 57% 40% CHAR 1 50 28% 49% 33% CHAR 1 100 23% 40% 27% CHAR 1 500 9% 17% 11% CHAR 1 3,000 2% 3% 2% CHAR 1 6,000 1% 2% 1% CHAR 1 6,500 1% 1% 1% |
Type Size #(L) %K %E %B ------ ---- ----- ---- ---- ---- STRING 7 1 25% 48% 36% STRING 7 5 29% 54% 38% STRING 7 10 30% 50% 38% STRING 7 50 25% 41% 31% STRING 7 100 21% 34% 25% STRING 7 500 8% 13% 11% STRING 7 3,000 -1% 0% 2% STRING 7 6,000 -2% -1% 1% STRING 7 6,500 -2% -1% 1% |
bndrbnch.pas
En la Figura 8.21 está
una pequeña parte de los datos que contiene el archivo
Binder.666, listado usando el procedimiento
BLog.ReOrder(). Se
muestra el tiempo relativo adicional que duran los tres tipos de
lista parametrizados con Binder.pas con respecto a la
lista tradicional LstC.pas. Salta a la vista
inmediatamente que cuando las listas son muy pequeñas, la
disparidad es enorme, pues una lista parametrizada a través
de Binder.pas toma más de 50%
adicional de tiempo para ejecutar. Sin embargo, conforme crece el
tamaño de la lista esa disparidad desaparece, hasta hacerse
prácticamente nula. ¿Qué está pasando?.
La respuesta es muy sencilla, y para obtenerla basta examinar con
cuidado la implementación de los procedimientos que se han
usado para sacar las mediciones, como por ejemplo la de la
Figura 8.10. Cuando la lista es
muy pequeña, se emplea una buena porción del tiempo
de ejecución en manipular el elemento de la lista, y para
esto hay que invocar sus operaciones a través de la unidad
Binder.pas, que tiene que hacer varias conversiones
de punteros antes de invocar las operaciones del elemento
contenido. En contraste, en el caso de la lista no parametrizable,
las invocaciones se hacen directamente, sin manipular punteros o
hacer llamados a los procedimientos intermedios de
Binder.pas que atrasan la ejecución.
Conforme las listas son más grandes, la mayor parte del
esfuerzo de computación se gasta en ejecutar el
método TList.Lpos(n), que encuentra el
n-ésimo elemento de la lista saltando de
elemento en elemento, pero siempre comenzando desde el primero. El
diferencial de tiempo baja cuando crece la proporción de
veces que se ejecuta TList.Lpos(n) con respecto a la
cantidad de invocaciones a los métodos del elemento
contenido. Los procedimientos Copy_List() tienen
complejidad cuadrática, y es cuando la cantidad de
elementos se hace mayor que el comportamiento cuadrático
surge. El hecho de que cuando ya hay muchos elementos los tiempos
de ejecución sean muy similares, implica que el costo de
manipular enlaces en la lista es el mismo en las implementaciones
tradicionales, representadas por LstC.pas, y en las
listas parametrizadas con Binder.pas. Esto se deduce
de que, conforme las
operaciones fundamentales del
contenedor son las más, los tiempos de ejecución de
todas las listas parametrizadas se acercan al rendimiento de la
lista de referencia, TLstC.
La ineficiencia de Binder.pas está en la
invocación a los métodos del elemento contenido, no
en la ejecución de las operaciones del contenedor. En gran
parte, el tiempo de ejecución de los métodos de
TBinder se está desperdiciando haciendo los
cambios de contexto que implica invocar una subrutina. Se puede
hacer otra observación: en algunas ocasiones los
métodos de TBinder desperdician tiempo
ajustando y desajustando punteros, para convertir un puntero al
campo de enlace en un puntero al elemento, y viceversa. Este
trabajo hay que hacerlo porque el contenedor utiliza punteros a
los campos de enlace, pero los métodos del elemento
contenido sólo trabajan con punteros al principio del elemento.
Por eso cuando la lista es muy pequeña, con unos pocos
elementos, el diferencial de tiempo de ejecución es muy
alto. Esto quiere decir que si se usa un lenguaje como C++, que
permite desarrollar procedimientos en línea
(inline), entonces todas las ineficiencias de usar
Binder.pas desaparecerían, y quedarían
únicamente sus ventajas. Esta es una gran noticia, pues
muestra que es posible parametrizar contenedores, compartir la
implementación de los algoritmos y proteger el
código fuente sin pérdida de eficiencia.
La implementación actual de Binder.pas es muy
simple. Por ejemplo, cada vez que se necesita ajustar un puntero,
se invoca un procedimiento. Así se facilita depurar la
implementación de Binder.pas, pero se puede
lograr mayor eficiencia si se desarrolla en línea este
código que ajusta punteros. Otra fuente grande de
ineficiencia está en la invocación a los
métodos del elemento contenido, que requiere examinar una
tabla de punteros a rutinas para saber si el programador cliente
ha definido un método para su objeto. En este caso, hay que
examinar los argumentos y luego saltar al método. Cuando
éste retorna, saltar de vuelta al programa llamador.
Pareciera simple lograr que el salto desde el programa llamador
sea directo al método, pero como la invocación al
método del elemento se hace a través de un ligador,
de tipo TBinder, siempre es necesario hacer por lo
menos el salto desde el método de TBinder
hasta el del elemento. A menos que el compilador provea ayuda
especial para implementar contenedores, similar al que provee para
implementar el poliformismo mediante operaciones virtuales, el
costo de invocar los métodos de un contenedor será
un poquito más alto que el de invocar un
método virtual.
También es muy importante observar que lo que aumenta al
usar Binder.pas es el tiempo de ejecución de
los métodos del contenedor, pero eso no implica que haya un
aumento significativo en el tiempo de ejecución del
programa. Esto ocurre porque el tiempo que un programa emplea
ejecutando el código del contenedor es relativamente
pequeño, en comparación con el tiempo que toma
ejecutar el programa. Por ejemplo, un sistema operativo tiene que
emplearse a fondo para encontrar cuál es la siguiente tarea
de mayor prioridad, para cederle tiempo de ejecución, y no
usa mucho tiempo accesando la cola de procesos, que podría
ser un contenedor parametrizado con Binder.pas. Si
del tiempo total de ejecución del sistema operativo, las
operaciones de acceso a la cola representan un 5%, y
si al usar Binder.pas esas operaciones sufren un
incremento de 50%, en total el incremento en el
tiempo de ejecución del sistema operativo será de un
2.5% (5%×50% = 2.5%). Ese
tiempo se puede pagar simplemente usando un procesador un poquito
más rápido, o usando algo más de memoria.
#(L) % min % prm % max ---- ----- ----- ----- 1 9.09 34.89 69.23 2 12.28 38.35 66.67 3 13.64 37.38 65.66 4 11.50 36.51 69.17 5 12.37 36.98 67.53 6 12.68 36.19 64.71 7 12.79 36.57 66.35 8 10.24 35.07 62.35 9 13.17 36.63 63.20 10 13.07 35.66 61.92 20 10.86 33.75 59.84 30 12.85 33.33 58.42 40 7.22 30.98 55.84 50 6.42 30.34 53.30 |
#(L) % min % prm % max ---- ----- ----- ----- 100 4.94 24.60 45.00 150 4.79 21.31 38.81 200 4.43 18.61 34.27 250 4.33 16.76 30.58 300 4.08 15.02 27.77 350 4.17 13.88 25.34 400 3.81 12.70 23.43 450 3.76 11.84 21.72 500 3.55 10.98 20.36 1000 2.43 6.43 12.50 1500 1.43 4.64 9.26 2000 0.19 3.56 7.46 2500 -0.40 2.97 6.16 3000 -0.75 2.39 4.85 3500 -0.98 1.98 3.97 4000 -1.15 1.73 3.33 4500 -1.28 1.50 2.87 5000 -1.38 1.31 2.52 5500 -1.46 1.17 2.25 6000 -1.52 1.05 2.03 6500 -1.57 0.96 1.85 |
La cantidad de datos que bndrbnch.pas
recolectó es muy grande y variada, y se puede analizar
desde muchos puntos de vista. Como el objetivo de las pruebas es
ver cuán mal se ven las listas parametrizadas a
través de Binder.pas respecto de las listas
tradicionales, la primera estadística que se tomó es
graficar los peores tiempos de ejecución, respecto de la
cantidad de elementos de la lista, independientemente del tipo de
datos almacenado en la lista. Dado que las listas son de diferente
tamaño, se usó como tiempo peor aquel cuya
variación porcentual respecto del tiempo de la lista
TLstC fuera más amplia. En la
Figura 8.22 están los
tiempos relativos mínimo, promedio y máximo de
ejecución respecto de la lista de referencia,
LstC.pas (estos tiempos fueron obtenidos listando el
archivo Binder.666 con
BLog.MinPromMax()).
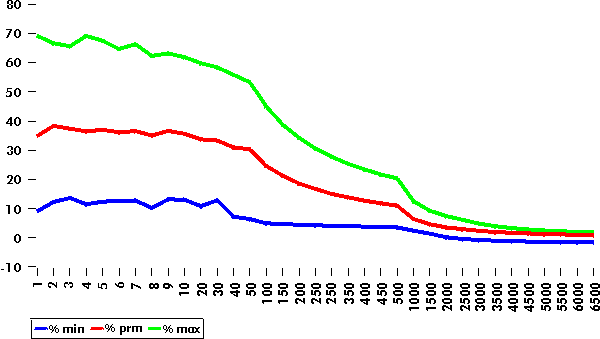
|
Siempre es más agradable examinar una gráfica que
analizar números y porcentajes. La
Figura 8.23 es la
gráfica que corresponde a los datos de la
Figura 8.22. Se nota claramente
que, al crecer la cantidad de elementos de la lista, los tiempos
de ejecución se hacen cada vez más similares; las
diferencias se dan en listas muy pequeñas, en las que el
sobretrabajo de usar
Binder.pas para manipular el elemento de la lista es
significativo.
Los números de la
Figura 8.22 sirven para sacar
estas conclusiones. Si la lista parametrizada es pequeña,
el
sobretrabajo de usar
Binder.pas es de alrdedor de un 40%.
Para las listas medianas la cifra baja a menos del
25%, y para listas grandes no hay diferencia
apreciable. Estos datos son válidos si se usa Pascal, pues
en C++ el panorama sería mucho mejor: muchas de las
ineficiencias del uso de Binder.pas, particularmente
el exceso de cambios de contexto que se produce al invocar las
operaciones del elemento contenido a través de un ligador,
se pueden evitar usando funciones que se desarrollen en
línea (inline). En otras palabras, la
tecnología que se desarrolla
en esta investigación funciona, y funciona
bien.
Otra observación interesante que se puede hacer al examinar
los datos colectados en el archivo Binder.666 es que
los tiempos para Copy_LstK() son mejores que los de
Copy_LstC() cuando el elemento de la lista es una
hilera 'STRING' de tamaño impar, lo que fuerza
a que el campo de enlace de la lista, que es el puntero
".next" en el caso de
TLstC, quede desalineado. Como para accesar el campo
de enlace de TLstC el compilador debe ajustar el
puntero, pues el campo ".next" aparece luego del
valor almacenado en la lista, cuando la cantidad de operaciones
que requieren usar el campo de enlace sea muy grande, como ocurre
por ejemplo cuando la lista tiene 3,000 o más elementos,
entonces el esfuerzo que hay que hacer en
LstC.pas se comienza a
notar, pues no es nulo. Esto quiere decir que un contenedor
implementado siguiendo el
paradigama de
Binder.pas es más eficiente para manipular los
campos de enlace, pues no hace más que ajustar punteros
para saltar de un campo de enlace a otro. En
contraposición, los contenedores que son programados de la
forma tradicional sí deben ajustar punteros para pasar de
un campo de enlace a otro, pero sólo en aquellos casos en
que el campo de enlace no está al principio del elemento
almacenado.
La observación del párrafo anterior es importante, pues tiene implícita una recomendación: Si se necesita implementar un contenedor que requiere mucha manipulación de los campos de enlace, entonces es mejor implementarlos siguiendo la técnica de parametrización desarrollada en este trabajo. Por ejemplo, seguramente de esta forma se puede mejorar la eficiencia de algunos algoritmos que trabajan con grafos, los que deben recorrer el contenedor a lo largo y ancho para obtener resultados.
Dado que el costo de usar Binder.pas no es
insignificante, cabe hacer la siguiente pregunta: ¿Es
necesario reimplementar Binder.pas para mostrar que
se puede aumentar la eficiencia, tal vez logrando que el
diferencial en tiempo de ejecución baje en todos los casos
a 20%, o mejor a 10%? La respuesta a
esta pregunta es no. Binder.pas pudo ser implementado
en lenguaje de máquina, para aumentar su eficiencia. Sin
embargo, en esta investigación se busca dar el primer paso
para consolidar la
tecnología: lograr que el
costo de usar contenedores parametrizables incremente solamente en
un 40% del tiempo de ejecución mediante una
implementación que no ha sido afinada, es un gran logro
importante y un buen sustento para la conjetura de que, si las
cosas se hacen bien, el diferencial puede reducirse con facilidad
a un 20%. Un buen análisis de rendimiento,
junto con un esfuerzo considerable, seguramente depararán
una implementación que penalice en no más de
10% el tiempo de ejecución.
Pero es mejor dejar las cosas aquí, y dedicar nuevos
esfuerzos a mejorar los resultados alcanzados, mas no en la
plataforma Turbo Pascal. La razón principal por la que se
ha usado el lenguaje Pascal para desarrollar este trabajo, es
precisamente para mostrar que se puede parametrizar contenedores,
con un buen grado de eficiencia, dentro de las restricciones de un
lenguaje que tiene limitaciones semánticas importantes. Sin
lugar a dudas, esto ha quedado demostrado con la
implementación de Binder.pas en Pascal, que es
un lenguaje que representa el mínimo común de los
lenguajes actuales, por lo menos en comparación con los
lenguajes más avanzados que se usan en aplicaciones de
calidad industrial: Ada y C++. Pero, si hay que mejorar la
implementación de Binder.pas, es mucho mejor
invertir esfuerzos en plasmar una biblioteca para el lenguaje C++,
que es mucho más usado que Pascal, y para el que existen
mejores herramientas. Una vez que la biblioteca C++ haya sido
compilada, podrá ser usada desde Pascal sin mayores
problemas.
Binder.pas
Conviene destacar las cualidades de los contenedores
parametrizados con Binder.pas, que van más
allá de cumplir con la lista de requerimientos definida en
la
sección 8.2.
Binder.pas pueden usarse en aplicaciones de tiempo
real o en las que los datos están almacenados en memoria
ROM (memoria de solo lectura, o Read Only
Memory), plataformas en donde no se puede usar memoria
dinámica porque todos los programas deben ser rentrantes y
muy eficientes.
Binder.pas es más
general que el método usual, que requiere que todos los
nodos enlazados en un contenedor residan en memoria
dinámica.Binder.pas puede ser la
única forma de reutilizar contenedores en un programa en
que el rendimiento es de importancia crucial. Muchas veces el
programador necesita evitar que los nodos de su contenedor residan
en memoria dinámica, y en estos casos solamente
Binder.pas es una respuesta adecuada.Binder.pas comparten la misma implementación,
lo que no ocurre si se usan plantillas o paquetes
genéricos. Esto abre la posibilidad para que los
contenedores sean un servicio más del sistema operativo,
pues al programador cliente se le pueden entregar bibliotecas tipo
DLL con la implementación de
los contenedores más usados.Binder.pas:
simplemente enlazar el elemento en el contenedor, o en varios
contenedores diferentes si eso fuera necesario. Enlazar en el
contenedor todos sus elementos es más eficiente que
copiarlos, pues reconectar punteros casi siempre requiere menos
recursos que obtener un nuevo nodo de la memoria dinámica,
y luego dejar ahí la copia del valor que se ha insertado en
el contenedor.Binder.pas, junto al
instanciador de plantillas CTPinst, representa un
enfoque mucho más congruente, completo y eficiente.Binder.pas, no es necesario definir todas las
operaciones básicas del
elemento que será almacenado en el contenedor, ni tampoco
se necesita que esas operaciones sean métodos virtuales.
Esto implica un ahorro sustancial, pues en cada instancia
almacenada en el contenedor se evita usar espacio para almacenar
el puntero a la
VMT del elemento. En otras palabras,
no hay que pagar el costo básico de usar
OOP.
Binder.pas provee implementaciones por defecto
para todas las
operaciones básicas, para
usar contenedores el programador cliente no se ve obligado a
definir e implementar métodos que nunca usará, pero
que son necesarios para lograr que el programa sea aceptado por el
compilador. El tamaño de los programas objeto se reduce,
pues el sistema de compilación no tiene que incluirles el
código de esos métodos.Tanto Ada como C++ han acostumbrado a los programadores a usar plantillas o paquetes genéricos, y cada vez hay más aplicaciones interesantes para esta construcción sintáctica. Una aplicación muy elegante está descrita en [Vel-97]: las plantillas se pueden usar para que las expresiones de aritmética de matrices sean compiladas de manera que en tiempo de ejecución la expresión sea evaluada de forma óptima, liberando así al programador de la preocupación de que, si usa expresiones de matrices, el programa que resulta puede no evaluar la expresión eficientemente. Pese a que hay buenas aplicaciones para las plantillas, en este trabajo se ha demostrado que se puede lograr la parametrización sin usarlas, lo que es bueno. Pero de esto no se puede concluir que las plantillas sean innecesarias.
Más bien la conclusión debe ser la siguiente: Si
agregarle plantillas a un lenguaje resulta demasiado oneroso,
entonces tal vez valga la pena agregarle únicamente
suficiente maquinaria sintáctica para lograr un objetivo
específico, como facilitar la parametrización. Para
esto, por ejemplo, sirve la construcción
TYPECAST de la
Figura 7.45.
La maquinaria para parametrizar contenedores que representa
Binder.pas se ha construido partiendo de un hecho muy
importante: los campos de enlace que manipula un contenedor dentro
de cada una de las instancias que contiene, no le pertenecen a esa
instancia contenida, sino que le pertenecen al contenedor. Lo que
esto implica es que para parametrizar contenedores hace falta
cambiar la percepción, en la mente del programador, sobre
qué es un campo de enlace.
Este cambio de actitud es similar al que debe experimentar un programador cuando aprende OOP después de usar durante mucho tiempo sólo programación procedimental. Al principio surge una fuerte resistencia a aceptar el nuevo paradigma porque la herramienta que el programador usa sirve para todas las aplicaciones, aunque algunas son un poco más complicadas de realizar sin OOP. En parte esto explica que hay incontables artículos que explican cómo simular OOP en un lenguaje procedimental.
En verdad, para parametrizar contenedores, no hace falta cambiar de paradigma de programación. Algunos programadores fanáticos de C++ hablan de la biblioteca estándar de plantillas STL como un nuevo paradigma de programación, y muestran programas que con STL se pueden escribir en unas pocas líneas, mientras que, si no se usa la biblioteca, se necesita gastar días y semanas reprogramando unos cuantos algoritmos básicos. En realidad, la parametrización es una técnica simple que, en unos pocos casos, le facilita al programador expresar un algoritmo, y no requiere de un cambio de mentalidad significativo por parte del programador. Agregarle a un lenguaje plantillas o paquetes genéricos no es un fin en sí mismo, pues lo que se busca es precisamente que los algoritmos parametrizables sean programas iguales a los demás.
Es fácil que un programador experimentado entienda
cómo parametrizar contenedores con Binder.pas,
pues la
técnica usada es muy simple:
basta hacerle ver lo importante que es que el contenedor sea
dueño de sus campos de enlace, pues para implementarlo sólo
hace falta escribir los algoritmos que los manipulan. El
único detalle que hay que prever es que, cuando se requiera
invocar alguna de las operaciones del elemento contenido, no se
puede hacer un llamado directo, sino que hay que usar el ligador
asociado al contenedor.
TYPE
Tinteger = OBJECT (List.TLink)
...
END; { Tinteger }
VAR
L : TList;
i : Tinteger;
BEGIN
...
L.Init; i.Init;
...
L.LinkAfter(L.Last, i);
...
END;
|
Para educar al estudiante que recién aprende su lenguaje de
programación, lo más expedito es decirle desde el
principio que, al implementar contenedores, no se puede delegar la
responsabilidad de manipular el campo de enlace en el elemento
contenido. Una forma simple de explicarlo es requerir que el
elemento sea un tipo derivado del campo de enlace del contenedor,
como se muestra en la
Figura 8.24. Por ejemplo, para
hacer una lista de números enteros, la declaración
del tipo Tinteger debe derivarse directamente de
List.TLlink. Con esta lista el estudiante puede
desarrollar un programa relativamente complejo; si en su programa
basta usar una sola lista, se evitan los problemas que se derivan
de que, al parametrizar por herencia, se pierde la
protección de la verificación fuerte de tipos del
compilador.
Al usar parametrización por herencia el estudiante no
percibe que exista una intromisión del contenedor en el
elemento contenido. Una vez que su programa ya ha sido depurado,
el profesor puede pedirle que lo modifique para que use un
contenedor parametrizado con Binder.pas; al
estudiante le costará poco entender que, para accesar el
elemento desde el contenedor, debe hacerlo por medio de un ligador
de tipo TBinder.
Esta forma de introducir la parametrización de contenedores
tiene la desventaja, por lo menos en Pascal, de que un elemento
sólo puede estar almacenado en un contenedor, pues Pascal no tiene
herencia múltiple. Pero esta limitación más
bien puede verse como una ventaja, pues una vez que el estudiante
entiende el
método para parametrizar con
Binder.pas, puede usar maquinaria como la que
representa el programa CTPinst, para que el mismo
elemento esté en varios contenedores.
Otra restricción de esta forma de aprendizaje es que el
estudiante estaría usando contenedores que no incluyen la
verificación fuerte de tipos. Pero como los primeros
proyectos programados que el estudiante debe realizar en general
son muy simples, el profesor puede aliviar esta desventaja si
asigna proyectos que no requieren usar contenedores con elementos
diferentes. En la práctica, es complicado definir un
proyecto en el que se necesita usar más de un contenedor,
máxime si es el primero que un estudiante resolverá.
De todas formas, después de usar simplemente herencia para
manejar un contenedor, el estudiante puede trabajar con
CTPinst para obtener programas que sí cuentan
con verificación fuerte de tipos. Ya a esas alturas
podrá apreciar las ventajas que representa contar con la
verificación fuerte de tipos que el compilador brinda.
En resumen, la receta para convencer a cualquiera de usar
parametrización en el estilo de Binder.pas es
la siguiente:
Binder.pas que funcione, y también con la de
algún contenedor. Por su utilidad y simpleza, lo
lógico es comenzar con List.pas.Binder.pas: aunque un
elemento contiene el campo de enlace, ese campo le pertenece al
contenedor y no al elemento.TList, lo que hay que
hacer es derivar directamente de List.TLlink.Binder.pas para accesar las operaciones del
elemento contenido. A estas alturas ya el aprendiz puede captar
la necesidad de usar un módulo intermedio,
Binder.pas, entre el contenedor y su elemento
contenido.CTPinst: verificación
fuerte de tipos y la capacidad de que un mismo elemento pueda
estar almacenado en varios contenedores
simultáneamente.
La barrera mental más importante que se debe vencer para
aceptar usar la parametrización, es la idea de que el
elemento contenido es dueño del campo de enlace del
contenedor, y en esa calidad tiene la responsabilidad de
manipularlo. Tal vez el mejor argumento para cambiar este panorama
es resaltar la modularidad adicional que comporta el uso de
Binder.pas, pues al elemento se le libera de cuidar
de algo que no le pertenece, o sea, que el elemento se torna en un
cliente del contenedor, por lo que debe ser servidor, y deja de
ser dueño, lo que lo libera de la responsabilidad de
manipular el campo de enlace. La modularidad en un sistema se
logra cuando las relaciones entre las partes son las menos, y las
más simples. O sea, que si el manejo del campo de enlace se
concentra en el contenedor, entonces aumenta la modularidad del
programa porque todos los elementos quedan liberados de manipular
los campos de enlace.
Queda una pregunta que responder: ¿cuándo debe enseñarse parametrización? Aunque la herencia y el polimorfismo son conceptos que el estudiante aprende en su primer curso de programación, ya sea en el contexto del lenguaje Pascal o de cualquier otro, en verdad para entender qué significa parametrización es necesario trabajar en programas que tengan un tamaño por lo menos mediano, y lo usual es que el estudiante se vea enfrentado con proyectos de este tipo hasta su segundo curso de programación. Por eso conviene que ya el estudiante domine el concepto de módulo y de compilación separada antes de introducirlo a temas de más profundidad, como parametrización. Lo que sí no debe hacerse es esperar hasta el posgrado para exponer al estudiante a estos temas: ya para cuando el estudiante toma el curso de estructura de datos debe entender bien los conceptos asociados a la parametrización.
![[<==]](../../img/back.gif)
|
|
![[==>]](../../img/next.gif)
|